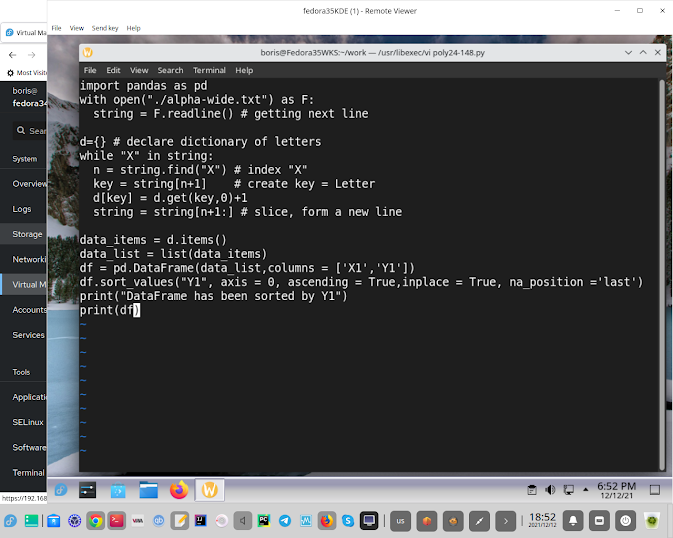
The following below is a not entirely trivial algorithm for students that creates a Python dictionary after scanning text according to the conditions of the problem, which gets converted into Pandas Dataframe and uploaded to SQLite database table to be analyzed via nested SQL Query.
Problem itself
A text file (beta-wide.txt) consists of many lines, each of which can contain letters from the set A, B, C, D, E, F. For the entire file, you need to determine which letter is most often forms substrings of maximum length. As an answer, you must enter a string consisting of the found letters, alphabetically without delimiters
(.env) [boris@fedora34server WORK]$ ll beta-wide.txt
-rw-rw-r--. 1 boris boris 59420 Dec 23 16:20 beta-wide.txt

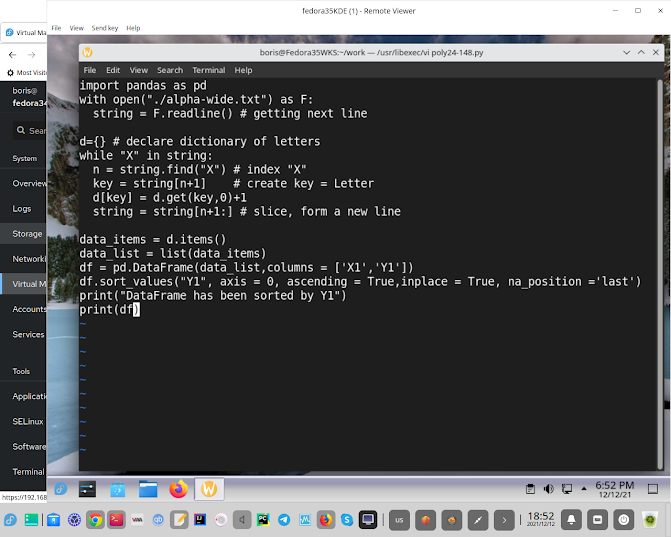
Python code building dictionary to be uploaded into SQLite table
via pandas DataFrame
import pandas as pd
import sqlite3
connection = sqlite3.connect('data_pandas.db')
c = connection.cursor()
c.execute('CREATE TABLE IF NOT EXISTS results(symv_name text, symv_qnt number)')
connection.commit()
seqLetter = []
file = open('./beta-wide.txt')
for line in file:
currLetrs = set()
curLen = 0
maxLen = 1
prev = ' '
for next in line:
if prev == next:
curLen +=1
if curLen > maxLen:
maxLen = curLen
currLetrs = set([next])
elif maxLen == curLen:
currLetrs.add(next)
else:
curLen =1
prev = next
seqLetter = seqLetter + list(currLetrs)
d = {}
for i in set(seqLetter):
key = i
d[key] = d[key] = d.get(key,0) + seqLetter.count(i)
data_items = d.items()
data_list = list(data_items)
df = pd.DataFrame(data_list, columns= ['symv_name','symv_qnt'])
df.to_sql('results', connection, if_exists='replace', index = False)
query = "SELECT * FROM results WHERE symv_qnt = (SELECT max(symv_qnt) FROM results)"
data = pd.read_sql_query(query,connection)
print(data)